TL;DR
ES 中的索引想要减小体积,可以尝试通过如下几个方法实现:
- 使用合适的模板字段映射类型
- 减少不必要的字段
- 对无需检索的字段关闭分词
此外索引个数不宜过多,影响集群操作以及集群恢复速度,适当关闭,合并,提前建立索引。
减小索引体积
ES 中的记录文件会存储到磁盘上,鉴于当前磁盘存储价格相当低廉,减小索引空间占用对于外存来说,意义并不是特别重大,当然数据量过大也会对写入速度有负面影响。
索引过大同时还会影响 Heap 内存的使用量,ES 作为搜索引擎时,有倒排索引用于关联关键字与文档,同时还有非倒排索引,即 fileddata 用于排序和聚合,在 ES 作为 TSDB 使用时,如果按照 ES 的默认设置,全部保存到内存中,很容易撑爆内存,组内在多年以前刚使用 ES 时,就发生过多次的内存爆掉导致集群挂掉的情况。
可以尝试通过下面的一些方法处理索引。
使用合适的模板字段映射类型
让我们先来看一个有多个数字字段的索引,这个索引用于记录每分钟接口调用的汇总情况,具体数据如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "200-500": 0, "max": 5070000000, "length": 8200000000, "count": 60000, "900-2s": 0, "500-900": 1, "5s+": 0, "url": "/get/info", "2xx": 6, "3xx": 0, "min": 47000, "type": "minute", "@timestamp": "2017-09-05T16:22:00.000Z", "4xx": 0, "size": 1928, "<80": 5, "80-200": 0, "5xx": 0, "domain": "sample.com", "@version": "1", "2s-5s": 0, "id": "cae573eadeaedaeeb1e3fe3680001c45" } |
由于 length 这一字段已经超越了 integer 能表示的范围, 最开始设定索引的同学没有多想,为了以防万一,把这个索引的所有数字字段都映射到了long类型。
这个索引在72w条记录时,索引大小高达 287.91MB。
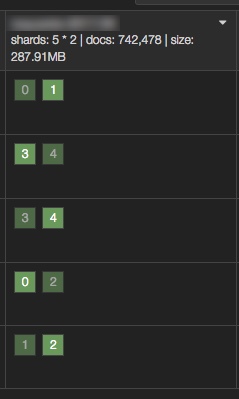
事实上,具体分析一下,有很多字段完全不会超过 integer 的表示范围,所以只要将特定的几个字段映射设置为 long 即可:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
... "length": { "index": "not_analyzed", "doc_values": true, "type": "long" }, "size": { "index": "not_analyzed", "doc_values": true, "type": "long" }, "count": { "index": "not_analyzed", "doc_values": true, "type": "integer" }, ... |
更改映射之后,同样的数据集的占用有了明显的改观:
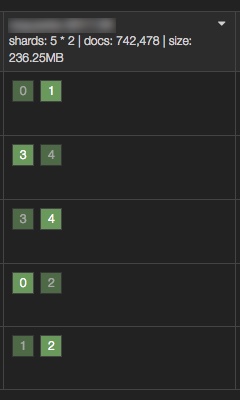
从 287.91MB 降低到了 236.25MB,节省了 51.66MB 的空间。
减少不必要的字段
再次把目光投向数据本身,还有可以优化的空间吗?
当然有,每一个文档都有一个 type 字段,是 logstash 在读取上游数据时用于区分数据来源在 input 插件中增加的,这个字段的值在所有文档中都是一样的,这个值对于查询来说,并没有意义,可以考虑删除。
同样的 id 字段也可以优化。id 字段最开始的用途是为每一条记录指定一个唯一 id,在 logstash 写入 ES 时,指定文档的唯一 id(可以防止数据重复录入):
|
1 2 3 4 5 6 7 8 9 10 11 |
output { if (type == "minute") { elasticsearch { hosts => ["es.sample.com:9200"] flush_size => 10000 index => "minute-%{+YYYY.MM}" document_id => "%{id}" } } } |
然而,ES 会将 id 字段记录到 _id 字段中,同时在文档记录 id。这部分数据可以进行优化。
然而,通过在 filter 中直接通过 mutate 删除这些字段是不现实的,因为在 output 中还要使用。
解决的方案很简单,可以通过重写 @metadata 中的数据,然后删除这些字段,最后利用 @metadata 的数据完成这些字段现有的作用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
filter { mutate { add_field => { "[@metadata][id]" => "%{id}" "[@metadata][type]" => "%{type}" } remove_field => [ "id", "type" ] } } output { if ([@metadata][type] == "minute") { elasticsearch { hosts => ["es.sample.com:9200"] flush_size => 10000 index => "minute-%{+YYYY.MM}" document_id => "%{[@metadata][id]}" } } } |
如此处理之后,索引大小变化为 175.21MB :
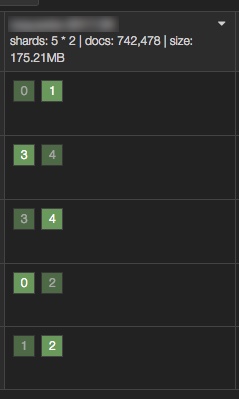
经过上述两个手段,索引大小减少了 112.7MB,瘦身比例 39.1%,效果显著。
关于 @metadata,可以在这里找到更多内容。
对无需检索的字段关闭分词
对所有字段开启分词对于和冗余字段一样是浪费,2.x 版本在模板文件中将对应字段设置为 not_analyzed 即可。
索引使用注意事项
索引个数
索引个数在日常使用中,主要影响两个方面,一个是 Master 的处理速度,一个是机群恢复的速度。
Master 会管理集群中的各个分片位置,索引一般都会有分片(shard)和副本(replica),这也是 ES 集群数据安全性的保证。
过多的索引会带来过多的 shard,shard 过多带来的问题首先是恢复速度,早期 1.x 版本的 ES 恢复速度极其感人,对集群之间的 IO 压力相当巨大。2.x 虽然大为改善,但是恢复速度是和 shard 个数正相关。
GitHub 上的一个 Issue Creating Index painfully slow on cluster with large indices 中提到:
When you create an index, that causes a change to the routing table. A cluster state update task is submitted to the nodes in the cluster. When that cluster state update task arrives, each node must process the new routing table to see if they need to remove indices, delete shards, start shards, etc. Currently, applying deleted shards is O(number of indices * number of shards). I opened #18788 to address this.
However, you’re still going to be hurting here. Having 10000 indices on two nodes with one replica is asking for pain. This means that you have at a minimum 10000 shards on each node if you have one shard per index, and maybe 50000 shards on each node if you’re using the default number of shards per index. Either way, this is way too many shards. So #18788 is not meant to address your issue directly, just improve performance for the general case. You’ll still need to do something about how many indices and shards that you have.
简单来说,ES 集群中如果索引数目过多,会直接影响到索引的新增和改动操作,因为这些操作是需要 Master 阻塞完成的。
如果集群发现超时 discovery.zen.ping.timeout 配置得过低,那么如果集群稍微压力巨大,甚至还会直接引起 Master 丢失,整个集群会进入一段时间的不可用阶段。
另一个方向上,ES 中的索引都会组织到文件中,如果索引个数太多,加上网络连接,可能会导致进程达到可以打开的 FD 的极限,出现 too many open files 问题,导致连接不上 ES ,造成服务不可用 ,虽然可以动态的进行修改,但是毕竟不是根本解决方案。
综上,可以定期合并一些按小时或者按天组织的小索引,这些小索引虽然占用空间不大,但是给 Master 和整个集群带来了管理成本。
合并索引
elasticsearch-dump 是一个基于 Node 编写的好工具,能方便的完成这一功能。
通过这个工具,可以先将小索引通过通配符 dump 到文件中,检查数据后写入新的合并的索引中。
|
1 2 3 4 |
./elasticdump/bin/elasticdump --input=http://es.sample.com:9200/pv-2016* --output=pv-2016.json ./elasticdump/bin/elasticdump --input=pv-2016.json --output=http://es.sample.com:9200/pv-2016/ |
之后通过 ES HTTP API 通过通配符关闭或者删除索引,减少活跃的索引个数。
提前建立索引
在系统低峰期,可以考虑提前创建好一段时间的索引文件,防止高峰时引发长时间阻塞。