概述
本文代码版本为1.11.8,手册原文来自于官网。
MySQL InnoDB可以设定ANSI SQL-92中规定的四个事务隔离级别,事务并发度和事务隔离级别成反比,事务隔离级别越高,并发度越低。
是否有锁操作,取决于当前的读取是快照读,还是当前读,快照读读取的是可见的历史版本,无需上锁,简单的读操作是快照读(SELECT无附加语句),其他都是当前读,需要加锁。
对无索引的数据,InnoDB会锁定全表的记录,但是会在扫描过程中释放不符合筛选规则的记录的锁定。
对于有索引的数据,需要具体分析,在RR这一级别,InnoDB通过GAP锁机制避免了幻读问题。
共享内存指在多处理器的计算机系统中,可以被不同中CPU访问的大容量内存。是众多进程间通信(IPC)方式中最快的一种,无需进行数据拷贝等操作,即可在各个进程之间共享数据。
PHP同样也提供了对共享内存操作的可能性,通过shmop扩展实现。
结合一个实际使用的场景,PHP daemon多进程从上游获取用户ID,需要与指定数据集去重,用户ID大约为12位的数字。要求是不能多去重(即不能存在误伤的判断),但是也不能少去重。
考虑到多进程处理时,需要考虑如何实现便捷,快速的进行判断用户ID已存在于数据集之中。在数据结构上可以使用的几种方法有:
下面分别说明三者的优缺点:
Bitmap(位图,以下不加区分的使用)的特点在于数据密度大时(即已排序的情况下,相邻数字间隔不大),是极为节省内存用量的数据结构。无论数字多大,在内存中只通过1 Bit进行表示。假设用1 Byte的空间进行数字的表示,数据集为[1,3,4,5,7],则这一组数据的位图可以表示为:
|
1 2 |
01011101 |
即便数字相当巨大,在已知最小值的情况下,同样通过同样大小的空间也可表示,如数据集为[100000001,100000003,100000004,100000005,100000007],同样也可以用同样一个位图进行表示,因为所有数字的都可以认为相对于100000000进行了偏移操作。
Bitmap操作起来速度与便利性也相当令人满意,只需要根据数字大小,找到对应的位,判断当前位的0/1值即可,位运算操作的速度之快无需多言。
然而,Bitmap的最大问题在于,如果存储的是数值的顺序信息,那么整个Bitmap的数据才是最有效的。即,如果已经数字本身是有序的,如从1开始,一直到10000,或者是有办法迅速的知道位置是1的数字的具体字面值,那么存储的位会更加的高效。
在存储用户ID这一个场景时,Bitmap不一定适用,因为用户ID可能会长于10位,如果把用户ID当成数字来看,同时考虑到可能存在的一些业务形态(6,8之类的靓号逻辑,4之类的避讳逻辑),可能得到的Bitmap就相当的“稀疏”(0过多,1过少),造成的结果就是内存的有效使用率降低。假设用户ID最大值是9999999999,仅仅在10位数的用户ID的情况下,为了包含所有的数字,需要开辟约1192.09MB大小的内存空间,当然实际应用中很可能会比这个要小,通过找到偏移值(获取比较集的最大最小值,确定偏移值,减少无用0的内存占用)、数据分块(比如前5位相同的比率大,把数字前5位作为一个集合,只生成后5位的Bitmap提高表示有效程度)等方式,但是又会引入一些其他的问题,或者效果不佳(比较集合中存在1和9999999999两个用户ID)或者是难于管理(前5位有上万种组合
)。
如果在可以接受误伤的情况下,有一个更优的方案,即布隆过滤器(Bloom filter),这是通过Bitmap可以完成的,综合速度和存储压力都较优方案。
Hash(哈希表)的特点在于快,理论上来说,Hash的查询和写入时间复杂度都是O(1)。
编程语言如果提供了Hash的数据结构,那么应用数据结构就成为了一个看起来不错选择了。
实际实现中,Hash存在的第一个可能存在的问题是Hash冲突的解决,如果用开放地址法(Open addressing)进行解决,可能的问题在于冲突之后查询下一个可用地址的次数过多,而用链表(Separate chaining)解决,则会存在退化的情况(所有值都hash到一个链表中)。不过这些问题一般来说都应该是在应用过程中由编程语言关心的。
这次应用限定了编程语言为PHP,那么从PHP的实现上来看看应用Hash是否可行。
PHP里的数组就提供了Hash的功能,PHP数组的便利程度无需多言,在去重这一个场景上,完全可以通过用户ID作为key,写入布尔值作为value,通过isset()方法快速的进行去重操作。
速度上我们可能不再担忧了,但是内存占用上呢?
目前PHP的最新版本为PHP 7.1.0,常规编译安装后,通过如下脚本获取0~1000000在数组中的内存占用情况:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<?php ini_set('memory_limit', '512M'); $repeat = isset($argv[1]) ? $argv[1] : 0; echo 'memory usage(B):' . memory_get_usage() . "\n"; $a = []; for($i = 0; $i < $repeat; $i++) { $a[sprintf("%07d", $i)] = '1'; } echo 'memory usage(B):' . memory_get_usage() . "\n"; |
运行结果为:
|
1 2 3 4 |
$ /usr/local/php7/7.1.0/bin/php array_mem_usage.php 1000000 memory usage(B):350688 memory usage(B):358099536 |
仅仅1000000的7位字符串作为hash key的数据集,就需要耗费超过341MB的内存。可是即便是作为文本文件,这些数据集在通过换行符号分隔的情况下,完全加载到内存只需要大约8MB的内存使用。是什么造成了如此大的差距呢?
从PHP的源码来看(源码目录下的Zend/zend_types.h),PHP数组通过HashTable这一个struct实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
typedef struct _zend_array HashTable; struct _zend_array { zend_refcounted_h gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar consistency) } v; uint32_t flags; } u; uint32_t nTableMask; Bucket *arData; uint32_t nNumUsed; uint32_t nNumOfElements; uint32_t nTableSize; uint32_t nInternalPointer; zend_long nNextFreeElement; dtor_func_t pDestructor; }; |
数据的实际存储部分即Bucket,对内存占用影响起到决定性作用的也正是Bucket这个数据结构,Bucket的定义为:
|
1 2 3 4 5 6 |
typedef struct _Bucket { zval val; zend_ulong h; /* hash value (or numeric index) */ zend_string *key; /* string key or NULL for numerics */ } Bucket; |
在Bucket中包含zval,zend_ulong,以及zend_string三种数据结构,下面分别来看看这几个数据结构。
zval的定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
typedef struct _zval_struct zval; struct _zval_struct { zend_value value; /* value */ union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar type, /* active type */ zend_uchar type_flags, zend_uchar const_flags, zend_uchar reserved) /* call info for EX(This) */ } v; uint32_t type_info; } u1; union { uint32_t next; /* hash collision chain */ uint32_t cache_slot; /* literal cache slot */ uint32_t lineno; /* line number (for ast nodes) */ uint32_t num_args; /* arguments number for EX(This) */ uint32_t fe_pos; /* foreach position */ uint32_t fe_iter_idx; /* foreach iterator index */ uint32_t access_flags; /* class constant access flags */ uint32_t property_guard; /* single property guard */ } u2; }; |
zval中又包含zend_vlaue,那么通过zend_value的定义:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
typedef union _zend_value { zend_long lval; /* long value */ double dval; /* double value */ zend_refcounted *counted; zend_string *str; zend_array *arr; zend_object *obj; zend_resource *res; zend_reference *ref; zend_ast_ref *ast; zval *zv; void *ptr; zend_class_entry *ce; zend_function *func; struct { uint32_t w1; uint32_t w2; } ww; } zend_value; |
可以看出zend_value作为一个union至少要占用8个字节(最大的内存占用来自于当中包含的zend_long,在Zend/zend_long.h中被定义为typedef int64_t zend_long;),所以,作为一个struct,zval会占用sizeof(value)+sizeof(u1)+sizeof(u2)=8+4+4=16 Bytes。
在Zend/zend_long.h中被定义为typedef int64_t zend_ulong;,所以会占用8 Bytes。
来看zend_string的定义:
|
1 2 3 4 5 6 7 |
struct _zend_string { zend_refcounted_h gc; zend_ulong h; /* hash value */ size_t len; char val[1]; }; |
其中zend_refcounted_h的定义为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
typedef struct _zend_refcounted_h { uint32_t refcount; /* reference counter 32-bit */ union { struct { ZEND_ENDIAN_LOHI_3( zend_uchar type, zend_uchar flags, /* used for strings & objects */ uint16_t gc_info) /* keeps GC root number (or 0) and color */ } v; uint32_t type_info; } u; } zend_refcounted_h; |
可以看到zend_refcounted_h的空间占用为sizeof(refcount)+sizeof(u)=4+4=8 Bytes。
size_t这里需要注意,因为在64位OS上编译,这里会占用8 Bytes。
结构成员val用于存储key的值,由于key都是7位长的字符串,所以这里会占用7 Bytes。
所以,在这里,空间占用为8+8+8+7=31 Bytes。
综上,直接统计数据结构的大小已经能明显看到PHP提供Hash是相当占用内存的,出于这个方面的考虑,基本可以认定Hash不适合当前的应用场景。
可能有人会说,Array算是什么办法,但是对于特定情况,Array确实可以使用。
比如C语言的数组,是在内存中的一片连续空间,也就是说,实际上内存的占用就是数据个数乘以单个数据需要占用的空间。从这个角度来看,是没有太多的内存浪费的。
当然PHP的数组不能这么看,因为PHP的数组仍然有太多的冗余信息。
数组的“缺点”在于查找的耗时。线性查找的耗时几乎让人无法接受,那么如果数据可以是有序的,通过二分查找耗时将会大大降低。
1M的数据,只需要通过至多10次查找即可判断对应的值是否存在。
从数据特点和存储用量来考虑,同时考虑到查询速度,Array在这个场景下胜出。
PHP可以使用共享内存,作为最简单的IPC方式,并且使用方式相当简单,PHP的shmop扩展中提供了对共享内存的操作能力。
共享内存在PHP的创建和打开工作是通过shmop_open方法实现的。定义如下:
|
1 2 |
int shmop_open ( int $key , string $flags , int $mode , int $size ) |
PHP的共享内存的创建实际上是通过shmget这一系统调用实现的,参见shmop扩展源码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
PHP_FUNCTION(shmop_open) { zend_long key, mode, size; struct php_shmop *shmop; struct shmid_ds shm; char *flags; size_t flags_len; if (zend_parse_parameters(ZEND_NUM_ARGS(), "lsll", &key, &flags, &flags_len, &mode, &size) == FAILURE) { return; } // 其他代码 if (shmop->shmflg & IPC_CREAT && shmop->size < 1) { php_error_docref(NULL, E_WARNING, "Shared memory segment size must be greater than zero"); goto err; } shmop->shmid = shmget(shmop->key, shmop->size, shmop->shmflg); // 创建共享内存 if (shmop->shmid == -1) { php_error_docref(NULL, E_WARNING, "unable to attach or create shared memory segment '%s'", strerror(errno)); goto err; } // 其他代码 shmop->addr = shmat(shmop->shmid, 0, shmop->shmatflg); // 申请or打开的共享内存映射到当前进程的虚拟内存空间 if (shmop->addr == (char*) -1) { php_error_docref(NULL, E_WARNING, "unable to attach to shared memory segment '%s'", strerror(errno)); goto err; } RETURN_RES(zend_register_resource(shmop, shm_type)); err: efree(shmop); RETURN_FALSE; } |
shmget返回的值是一个类似文件描述符的存在,因为它并不是一个真正的文件描述符,所以我们实际上的操作依据仅仅上是一个全局唯一的数字,用来表示共享内存。同时通过shmat系统调用将共享内存映射到当前进程的地址虚拟空间之中。
共享内存打开方法中的第一个参数指定的key,是标识这一共享内存片段的依据,需要全局唯一,一个方法就是通过一个确实存在的文件,利用ftok系统调用,生成一个全局唯一的key。文件名不是决定key值的决定因素,决定因素是文件的inode号。
|
1 2 |
void shmop_close ( resource $shmid ) |
关闭的实现的是通过shmdt系统调用完成的。在扩展的MINIT阶段,通过zend_register_list_destructors_ex方法注册了资源析构方法为rsclean,对共享内存的的ID看做是资源(Resource)。
|
1 2 3 4 5 6 7 |
PHP_MINIT_FUNCTION(shmop) { shm_type = zend_register_list_destructors_ex(rsclean, NULL, "shmop", module_number); return SUCCESS; } |
在调用这一方法时,通过资源删除APIzend_list_close调用注册的rsclean方法完成对资源的释放。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
PHP_FUNCTION(shmop_close) { zval *shmid; struct php_shmop *shmop; if (zend_parse_parameters(ZEND_NUM_ARGS(), "r", &shmid) == FAILURE) { return; } if ((shmop = (struct php_shmop *)zend_fetch_resource(Z_RES_P(shmid), "shmop", shm_type)) == NULL) { RETURN_FALSE; } zend_list_close(Z_RES_P(shmid)); } |
而rsclean的实现如下:
|
1 2 3 4 5 6 7 8 |
static void rsclean(zend_resource *rsrc) { struct php_shmop *shmop = (struct php_shmop *)rsrc->ptr; shmdt(shmop->addr); efree(shmop); } |
对共享内存ID进行了shmdt操作,同时释放了的申请共享内存操作结构体。
|
1 2 |
bool shmop_delete ( resource $shmid ) |
这一个方法中,是shmctl系统调用的表现的时候了。删除一段共享内存只需要将系统调用中的第二个参数设定为IPC_RMID即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
PHP_FUNCTION(shmop_delete) { zval *shmid; struct php_shmop *shmop; if (zend_parse_parameters(ZEND_NUM_ARGS(), "r", &shmid) == FAILURE) { return; } if ((shmop = (struct php_shmop *)zend_fetch_resource(Z_RES_P(shmid), "shmop", shm_type)) == NULL) { RETURN_FALSE; } if (shmctl(shmop->shmid, IPC_RMID, NULL)) { php_error_docref(NULL, E_WARNING, "can't mark segment for deletion (are you the owner?)"); RETURN_FALSE; } RETURN_TRUE; } |
当然,删除共享内存也可以通过Linux中的ipcrm命令完成,如ipcrm的man中提到的,如果知到key(即创建/打开部分提到的共享内存全局唯一的标识)则使用-M参数,知道ID则使用-m参数。
|
1 2 3 4 5 6 |
-M shmkey Mark the shared memory segment associated with key shmkey for removal. This marked segment will be destroyed after the last detach. -m shmid Mark the shared memory segment associated with id shmid for removal. This marked segment will be destroyed after the last detach. |
|
1 2 |
string shmop_read ( resource $shmid , int $start , int $count ) |
读取的方法则是通过共享内存ID以及开始位置以及读取的长度获得一个字符串。
从实现上来看,以下几种情况会返回false并打印WARNING日志:
|
1 2 |
int shmop_write ( resource $shmid , string $data , int $offset ) |
实现上来说,实际上是通过memcpy将字符串的值复制到共享内存的指定位置。
开发过程中经常会使用MySQL的LOAD DATA功能,用于导入文件到MySQL的指定数据库表中。
若已经将文件切分为N个小文件再进行LOAD操作(例如使用Linux下的 split 工具),那么进度还是很容易把控的,可以通过直接查找当前正在进行导入的分片,进而判断当前的分片。
可是,如果某些情况下直接对一个大型的文件进行进行LOAD操作,整个过程并不能直观的获取当前的进度的,需要通过一些相对曲折的过程才能获取当前LOAD的进度。
Linux中的/proc虚拟文件系统是一个非常有趣的部分,这一个目录并不是包含了一些常规意义上的文件,而是表征了进程的部分运行时信息。部分Linux工具更是可以直接用读取目录中的部分信息来替代[1]。
在/proc下可以看到大量的名为数字的目录,这些数字正是进程的pid。而cd到其中任何一个目录下,可以看到类似的信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
/proc/18458$ ll 总用量 0 dr-xr-xr-x 2 root root 0 3月 29 10:48 attr -rw-r--r-- 1 root root 0 4月 3 21:34 autogroup -r-------- 1 root root 0 4月 3 21:34 auxv -r--r--r-- 1 root root 0 4月 3 21:34 cgroup --w------- 1 root root 0 4月 3 21:34 clear_refs -r--r--r-- 1 root root 0 1月 27 14:44 cmdline -rw-r--r-- 1 root root 0 4月 3 21:34 comm -rw-r--r-- 1 root root 0 4月 3 21:34 coredump_filter -r--r--r-- 1 root root 0 4月 3 21:34 cpuset lrwxrwxrwx 1 root root 0 4月 3 21:34 cwd -> / -r-------- 1 root root 0 3月 18 10:31 environ lrwxrwxrwx 1 root root 0 2月 23 13:24 exe -> /usr/local/nginx/sbin/nginx dr-x------ 2 root root 0 3月 29 10:48 fd dr-x------ 2 root root 0 4月 3 21:34 fdinfo -r-------- 1 root root 0 4月 3 21:34 io -rw------- 1 root root 0 4月 3 21:34 limits -rw-r--r-- 1 root root 0 4月 3 21:34 loginuid -r--r--r-- 1 root root 0 4月 3 21:34 maps -rw------- 1 root root 0 4月 3 21:34 mem -r--r--r-- 1 root root 0 4月 3 21:34 mountinfo -r--r--r-- 1 root root 0 4月 3 21:34 mounts -r-------- 1 root root 0 4月 3 21:34 mountstats dr-xr-xr-x 5 root root 0 4月 3 21:34 net dr-x--x--x 2 root root 0 4月 3 21:34 ns -r--r--r-- 1 root root 0 4月 3 21:34 numa_maps -rw-r--r-- 1 root root 0 4月 3 21:34 oom_adj -r--r--r-- 1 root root 0 4月 3 21:34 oom_score -rw-r--r-- 1 root root 0 4月 3 21:34 oom_score_adj -r--r--r-- 1 root root 0 4月 3 21:34 pagemap -r--r--r-- 1 root root 0 4月 3 21:34 personality lrwxrwxrwx 1 root root 0 4月 3 21:34 root -> / -rw-r--r-- 1 root root 0 4月 3 21:34 sched -r--r--r-- 1 root root 0 4月 3 21:34 schedstat -r--r--r-- 1 root root 0 4月 3 21:34 sessionid -r--r--r-- 1 root root 0 4月 3 21:34 smaps -r--r--r-- 1 root root 0 4月 3 21:34 stack -r--r--r-- 1 root root 0 1月 27 14:44 stat -r--r--r-- 1 root root 0 1月 27 15:55 statm -r--r--r-- 1 root root 0 1月 27 14:44 status -r--r--r-- 1 root root 0 4月 3 21:34 syscall dr-xr-xr-x 3 root root 0 4月 3 21:34 task -r--r--r-- 1 root root 0 4月 3 21:34 wchan |
各个目录的说明可以参考此处。
这里我们关注的地方是如何通过这些丰富的信息获取导入数据库的进度。
考虑到这一导入操作,实际上是利用了MySQL进行读取文件的操作,那么,只需要知道MySQL当前读取的文件位置,就可以了解到当前的进度了。
/proc/[PID]/fdinfo/这一目录正是解决这一问题的关键,这一目录包含了当前进程已打开的文件的信息,其中文件名正是文件描述符的名称,而相关信息则存储在这个只读文件之中。包含的信息形如:
|
1 2 3 |
/proc/18458/fd$ cat ../fdinfo/7 pos: 2293603 flags: 0102001 |
pos即文件读取游标的偏移值,也就是我们关注的已读取到的位置。
flags则是一个八进制数,表征当前文件的打开状态。
以上述打开的文件为例,这是一个Nginx打开的日志文件,通过lsof +fg -p [PID]可以看到这一文件打开使用的flag:
|
1 2 3 |
COMMAND PID USER FD TYPE FILE-FLAG DEVICE SIZE/OFF NODE NAME ... nginx 18458 root 7w REG W,AP,LG 8,7 2293603 4194313 /home/www/logs/access_log |
可以看到使用了W、AP、LG三个flag,而W对应的是O_WRONLY,AP对应的是O_APPEND,LG对应的的O_LARGEFILE,这三个常量的值一般可以在/usr/include/bits/fcntl.h中找到:
|
1 2 3 |
bits/fcntl.h:36:#define O_WRONLY 01 bits/fcntl.h:42:#define O_APPEND 02000 bits/fcntl.h:71:# define O_LARGEFILE 0100000 |
所以flags的值为何是0102001也可以解释了。
根据上述分析,首先我们直接找到正在进行LOAD操作的MySQL进程的PID,获取之后查看当前打开的文件(假设文件名为foo)在进程中的fd:
|
1 |
ls -l /proc/[PID]/fd | grep foo | grep -v grep | awk '{print $9}' |
获取fd之后,直接读取对应的fdinfo:
|
1 |
cat /proc/[PID]/fdinfo/[fd] |
根据pos可以知道当前已读取了的文件位置,进而获知LOAD进度。
以上。
PHP7作为迄今为止性能最强的PHP版本,希望通过一些测试来了解它在Nginx与Apache下的表现。数据仅供参考。
由于个人水平有限,对测试的理解可能有所偏差,如有错误麻烦指出。
测试环境一共分为两台机器,机器A用作PHP运行环境,机器B作为压测机。A与B的CPU均为12 x Xeon E5 + 16GB RAM。
两台机器位于同一网段。
测试工具使用ab。
为了便于测试,调整了内核参数:
|
1 2 |
net.ipv4.tcp_syncookies = 0 net.ipv4.tcp_tw_reuse = 1 |
测试使用的软件版本为:
Apache在httpd-mpm.conf中的配置为:
|
1 2 3 4 5 6 7 8 9 |
ServerLimit 512 <IfModule mpm_prefork_module> StartServers 25 MinSpareServers 25 MaxSpareServers 25 MaxClients 512 MaxRequestsPerChild 10000 </IfModule> |
由于Apache+modphp7与Nginx+PHP-FPM二者的工作模式差别较大,想要均衡的配置出一个均衡的测试比较环境很困难,从简单出发,考虑到Apache在上述配置下最大会fork出512个进程处理请求,将PHP-FPM最大进程数也设成512个,即:
|
1 2 3 4 5 |
pm = dynamic pm.max_children = 512 pm.start_servers = 25 pm.max_spare_servers = 25 pm.max_requests = 10000 |
测试主要针对三种操作进行:输出Hello World,Redis KV读取操作,输出phpinfo()。
选择Redis KV读取操作的目的主要想测试下这一常用扩展的在Apache与Nginx作为WebServer环境下的表现。
测试分为2组,分别在25并发以及512并发下进行,测试时长为1min,同时记录服务器的load情况。
关注的数据为:
测试从性能指标以及系统负载两个方面进行观察。
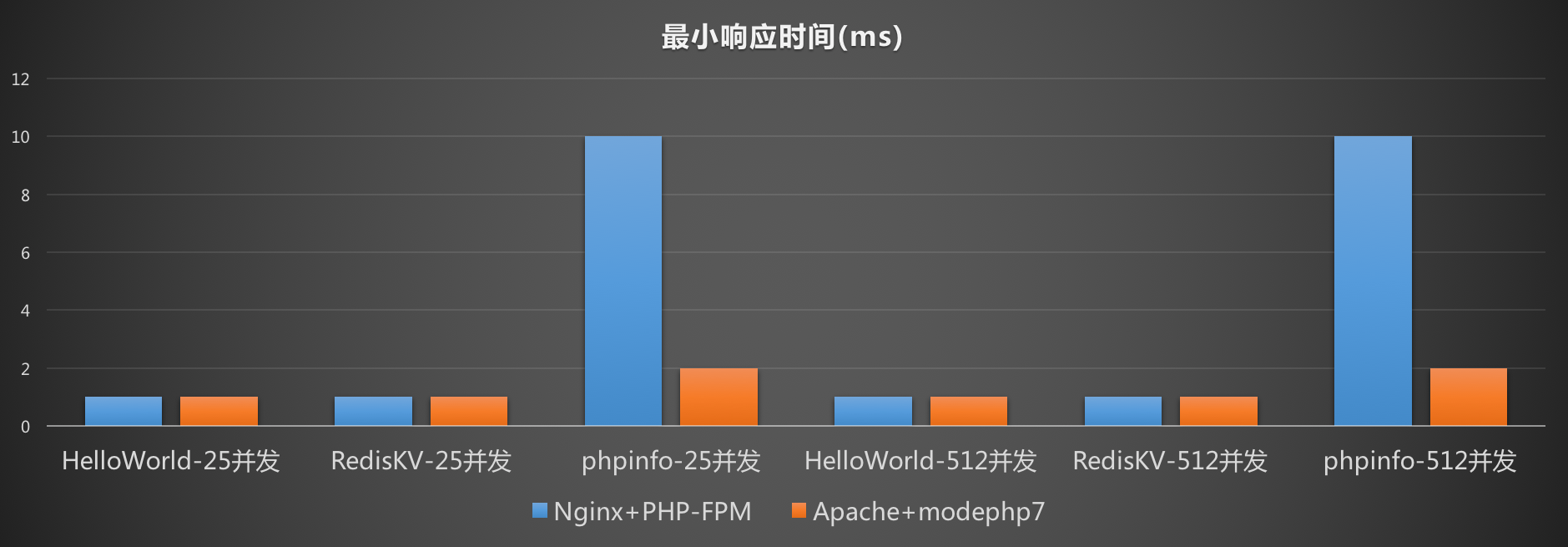
针对最小响应时间,并发数高低对最小响应时间没有显著的影响。在测试初期系统负载较低,测试数据应该表现最佳的阶段,推断二者在此阶段差距不大。
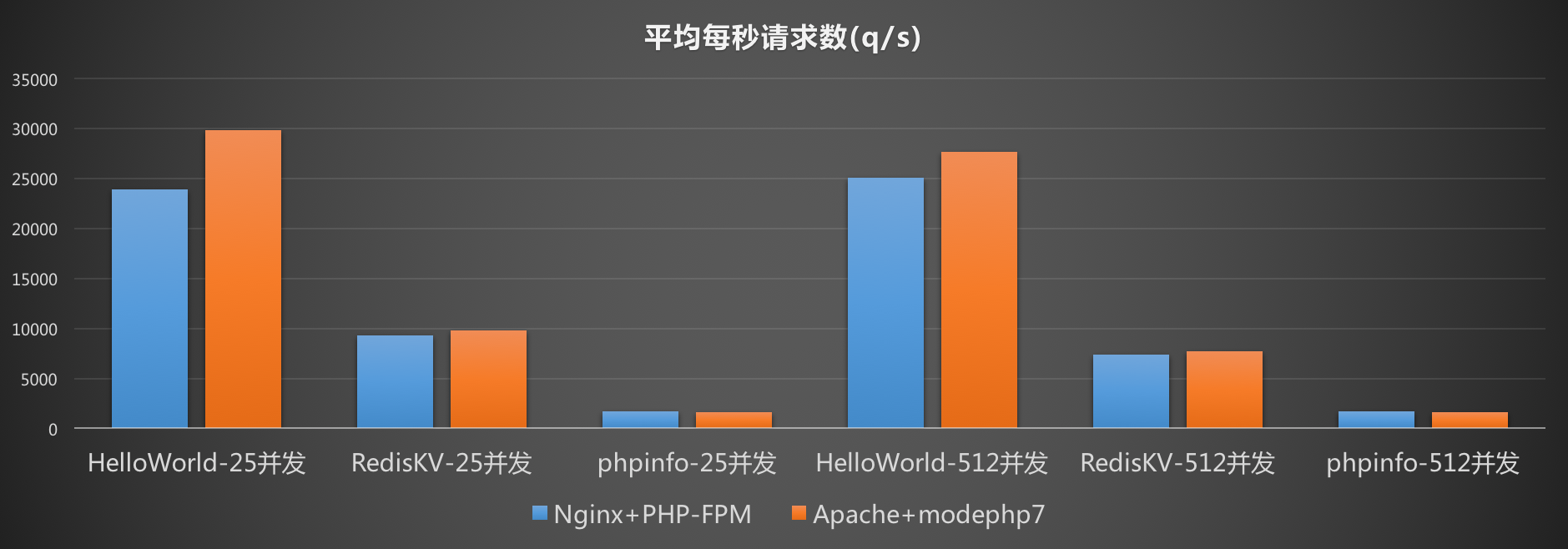
针对平均每秒请求数,Nginx+PHP-FPM的组合处理能力稍低于Apache+modphp7的组合,考虑到Nginx与PHP-FPM之间有网络通信(测试中采用了tcp socket)的开销,这个结果是可以接受的。高并发下考虑系统开销较大,请求处理能力会稍有下降。
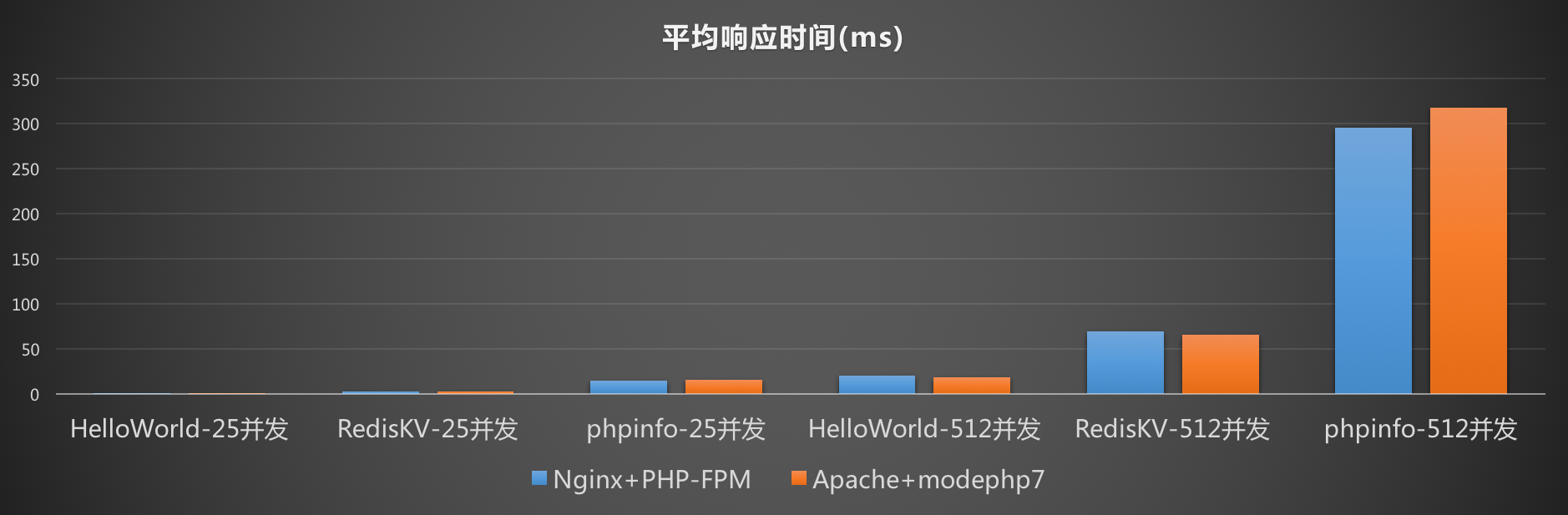
针对平均响应时间,高并发下同样由于系统开销较大的缘故,平均的请求处理响应时间升高也是符合预期的。
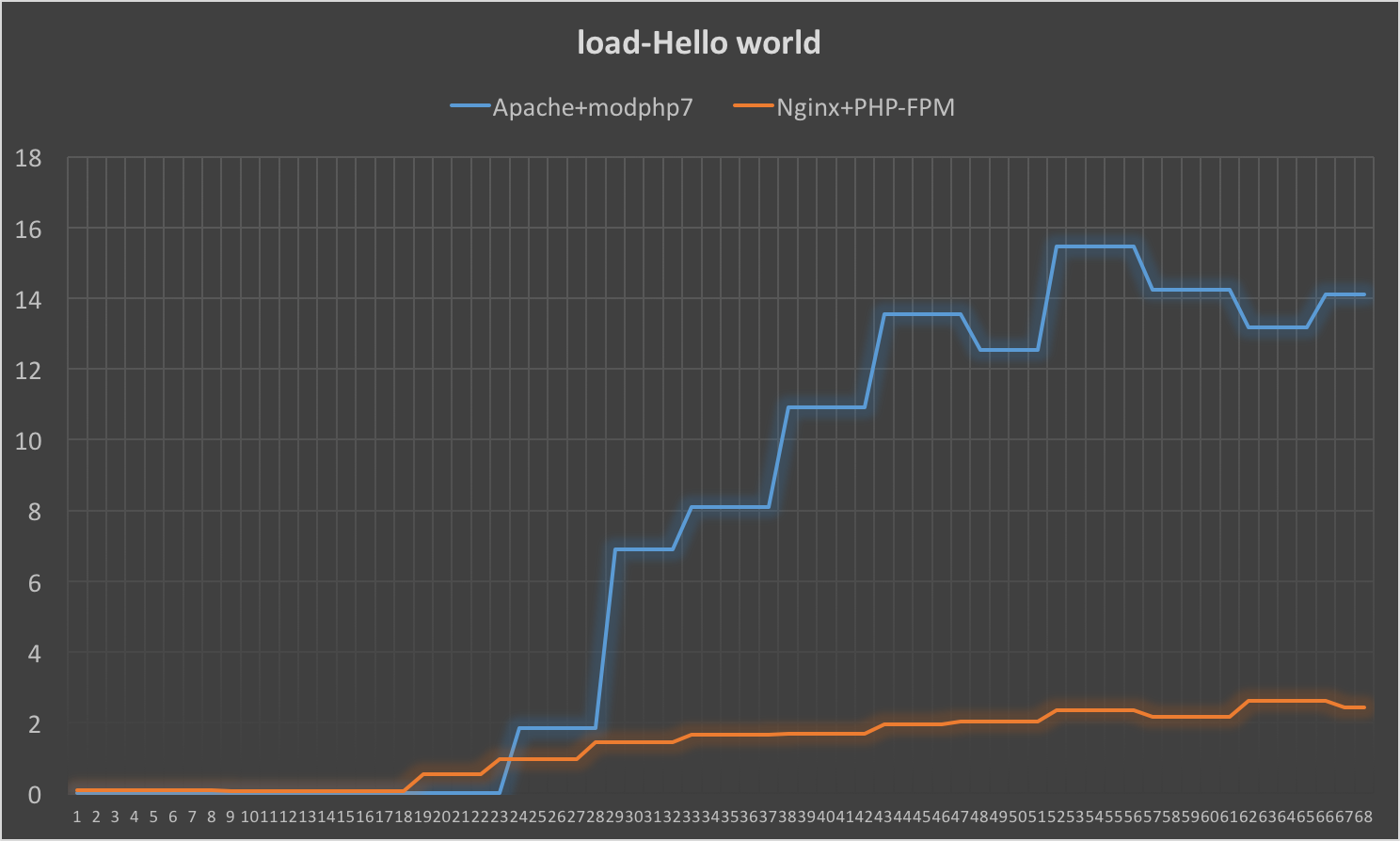
从性能指标上看,Nginx+PHP-FPM的组合与Apache+modphp7的组合在表现上没有巨大的差距,但是在系统负载上,Nginx+PHP-FPM的配置在高并发的情况下远优于Apache+modphp7的组合。 在512并发时,在测试Hello world时,系统load的表现就有巨大的差距:
同样的情况还出现在512并发之下对Redis KV操作的测试case之下:
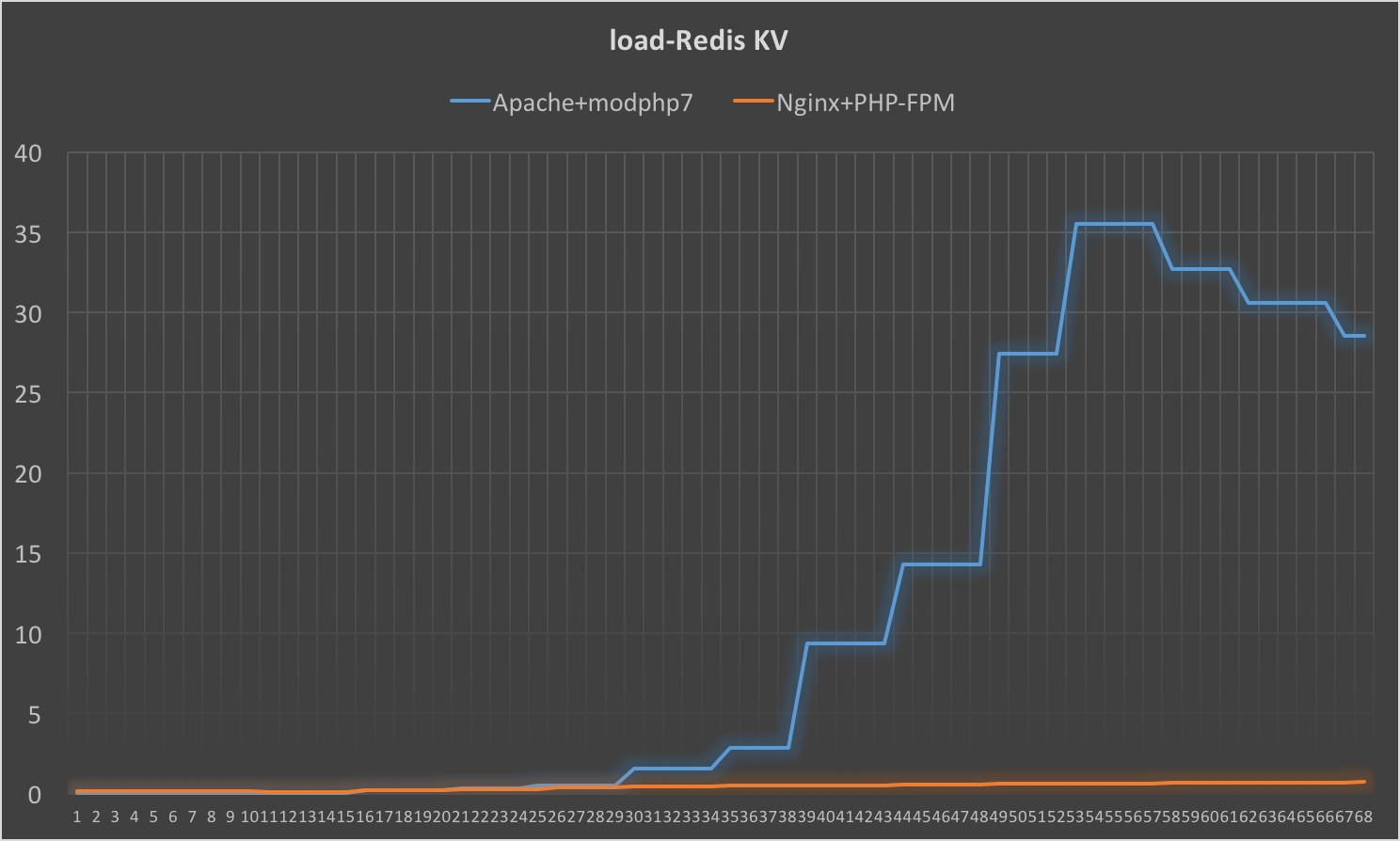
即便是在低并发(25并发)下,Redis KV此类需要操作网络资源的操作,Apache+modphp7在系统负载上的表现也差于Nginx+PHP-FPM:
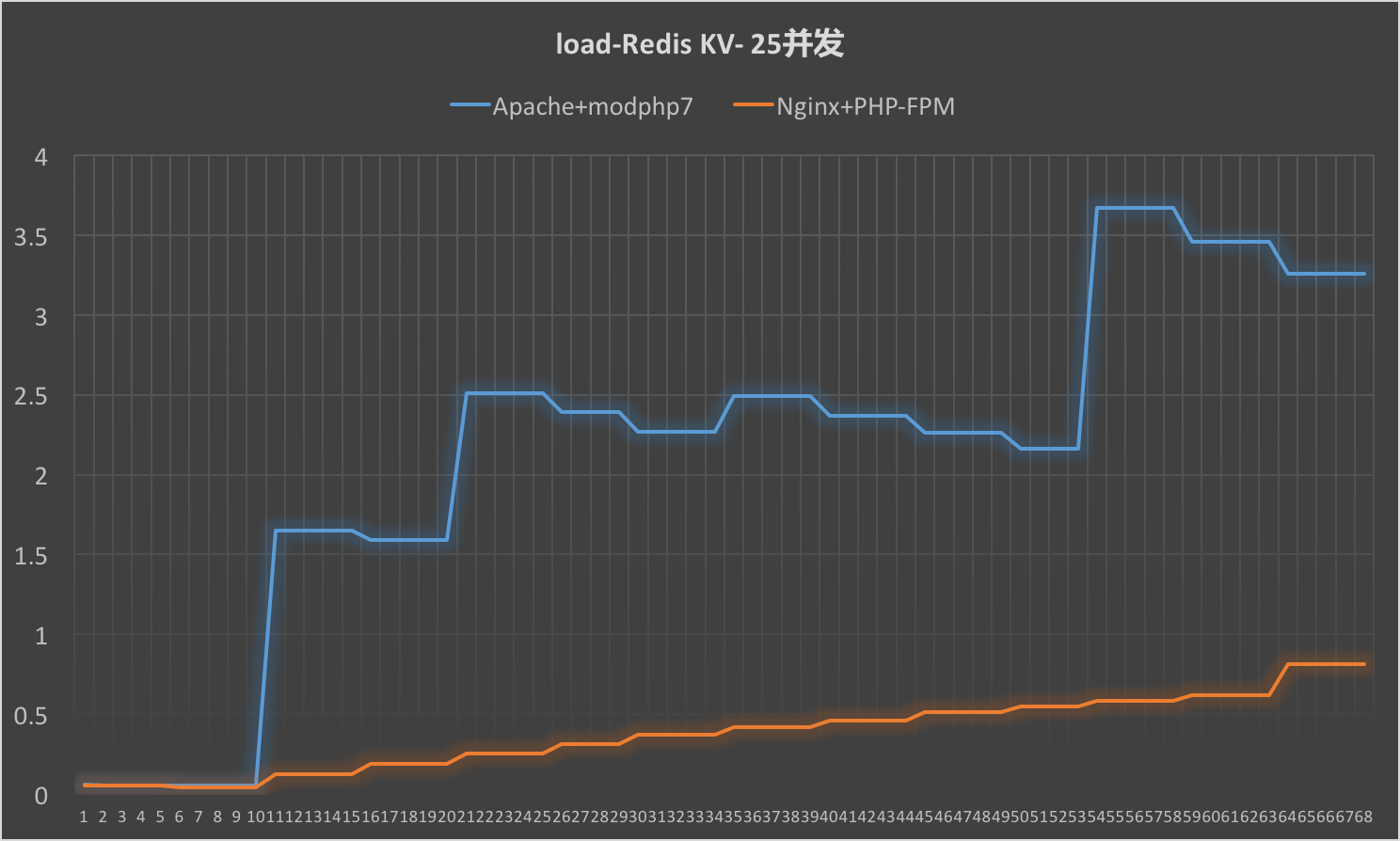
对于这类需要操作I/O的操作来说,Apache+modphp7的组合表现差于使用了异步I/O的Nginx与PHP-FPM的组合是符合预期的。
在测试phpinfo()输出时,虽然二者在load上的区别不大,但是Nginx+PHP-FPM的组合在进程数这一指标上完全占优:
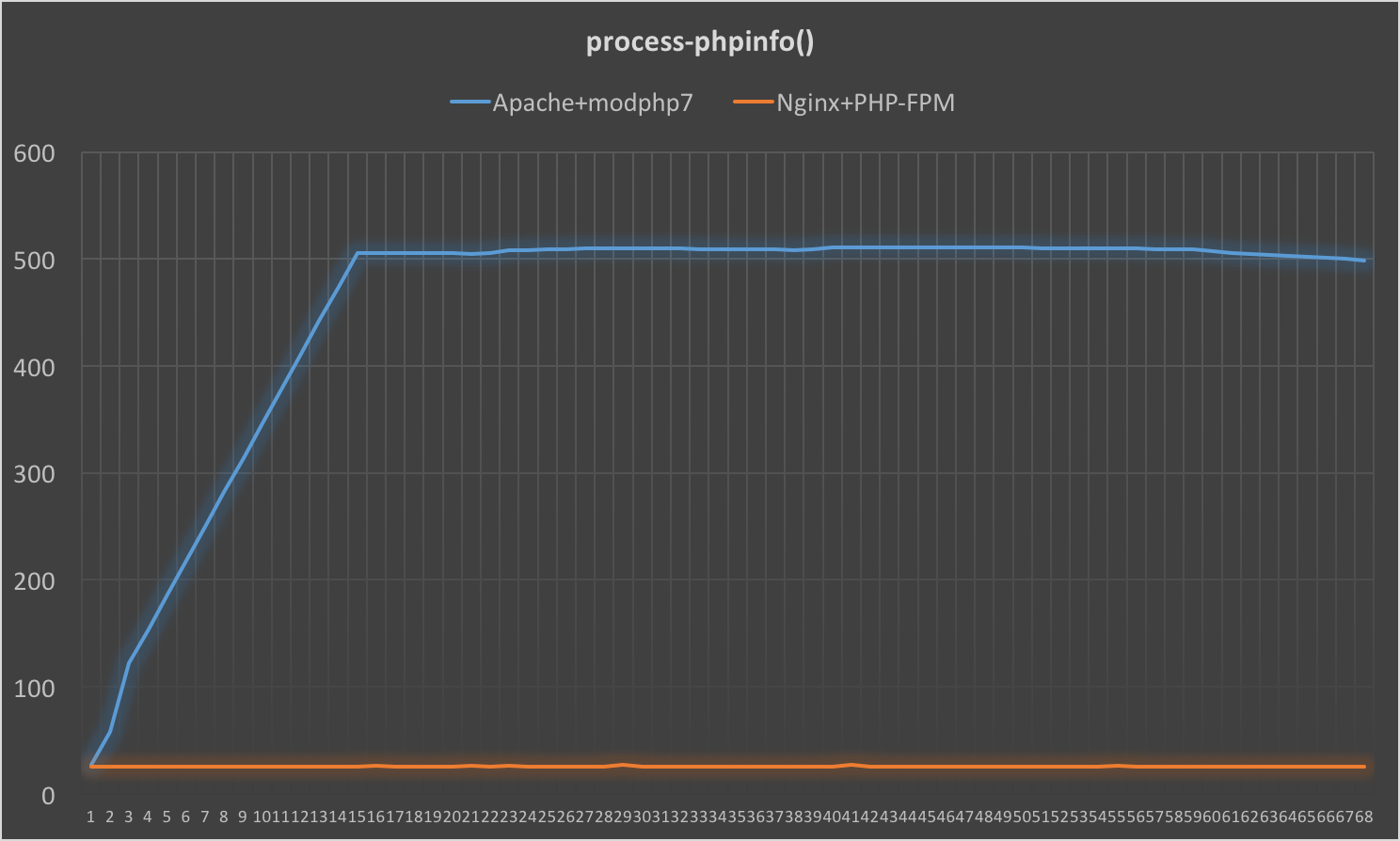
考虑到Nginx+PHP-FPM的组合无需fork出新的子进程处理新到的客户端请求,以及phpinfo()的执行时间较长这两个因素,同时fork子进程等操作属于消耗系统资源较大的操作,这个现象是符合预期的。
使用php7时,在性能上Apache+modphp7的组合与Nginx+PHP-FPM的组合相差无几,但对于系统负载上来说,Nginx+PHP-FPM组合综合表现优于Apache+modephp7的组合,可以推断Nginx+PHP-FPM的组合对于构建高并发的服务更有优势。
综合考虑,Nginx+PHP-FPM表现较优。